With C# 6 nearly upon us I thought it would be a good time to revisit some of the upcoming language features. A lot has changed since I last wrote about the proposed new features so let’s take a look at what’s ahead.
I think it’s fair to say that have mixed feelings about this release as far as language features go especially since many of my favorite proposed features were cut. I was particularly sad to see primary constructors go because of how much waste is involved with explicitly creating a constructor, especially when compared to the same activity in F#. Similarly, declaration expressions would have nearly fixed another of my least favorite things in C# – declaring variables to hold out parameters outside of the block where they’re used. Being able to declare those variables inline would have been a welcome improvement. That said, I think there are some nice additions to the language. Here’s a rundown of my top five favorite C# 6.0 language features in no particular order.
Auto-Property Initialization Enhancements
The auto-property initialization enhancements give us a convenient way to define an auto-property and set its initial value without necessarily having to also wire up a constructor. Here’s a trivial example where the Radius property on a Circle class is initialized to zero:
public class Circle
{
public int Radius { get; set; } = 0;
}
The same syntax is available for auto-properties with private setters like this:
public class Circle
{
public int Radius { get; private set; } = 0;
}
So we saved a few keystrokes by not needing a constructor. Big deal, right? If this were the end of the story, this feature definitely wouldn’t have made this list but there’s one more variant that I’m really excited about: getter-only auto-properties. Here’s the same class revised to use a getter-only auto-property:
public class Circle
{
public int Radius { get; } = 0;
}
Syntactically these don’t differ much but behind the scenes is a different story. What getter-only auto-properties give us is true immutability and that’s why I’m so excited about this feature. When using the private setter version, the class is immutable from the outside but anything inside the class can still change those values. For instance,
in the private setter version it would be perfectly valid to have a Resize method that could change Radius. Getter-only auto-properties are different in that the compiler generates a readonly backing field making it impossible to change the value from anywhere outside of the constructor. This is important because now, when combined with a constructor we have a fairly convenient mechanism for creating immutable objects.
public class Circle
{
public int Radius { get; }
public Circle(int radius)
{
Radius = radius;
}
}
Now this isn’t quite as terse as F#’s record types but by guiding developers toward building immutable types, it’s definitely a step in the right direction.
Using Static
Using static allows us to access static methods as though they were globally available without specifying the class name. This is largely a convenience feature but when applied sparingly it can not only simplify code but also make the intent more apparent. For instance, a method to find the distance between two points might look like this:
public double FindDistance(Point other)
{
return Math.Sqrt(Math.Pow(this.X - other.X, 2) + Math.Pow(this.Y - other.Y, 2));
}
Although this is a simple example, the intent of the code is easily lost because the formula is broken up by references to the Math object. To solve this, C# 6 lets us make static members of a type available without the type prefix via new using static directives. Here’s how we’d include System.Math’s static methods:
using static System.Math;
Now that System.Math is imported and its methods are available in the source file we can then remove the references to Math from the remaining code which leaves us with this:
public double FindDistance(Point other)
{
return Sqrt(Pow(this.X - other.X, 2) + Pow(this.Y - other.Y, 2));
}
Without the references to Math, the formula becomes a bit clearer.
A side-benefit of using static is that we’re not limited to static methods – if it’s static, we can use it. For example, you could include a using static directive for System.Drawing.Color to avoid having to prefix every reference to a color with the type name.
Expression-Bodied Members
Expression-bodied members easily count as one of my favorite C# 6 feature because they elevate the importance of expressions within the traditionally statement-based language by allowing us to supply method, operator, and read-only property bodies with a lambda expression-like syntax. For instance, we could define a ToString method on our Circle class from earlier as follows:
public override string ToString() => $"Radius: {Radius}";
Note that the above snippet uses another new feature: string interpolation. We’ll cover that shortly.
At first glance it may appear that this feature is somewhat limited because C#’s statement-based nature automatically reduces the list of things that can serve as the member body. For this reason I was sad to see the semicolon operator removed from C# 6 because it would have added quite a bit of power to expression-bodied members. Unfortunately the semicolon operator really just traded one syntax for an only slightly improved syntax.
If expression-bodied members are so limited why are they on this list? Keep in mind that any expression can be used as the body. As such we can easily extend the power of expression-bodied members by programming in a more functional style.
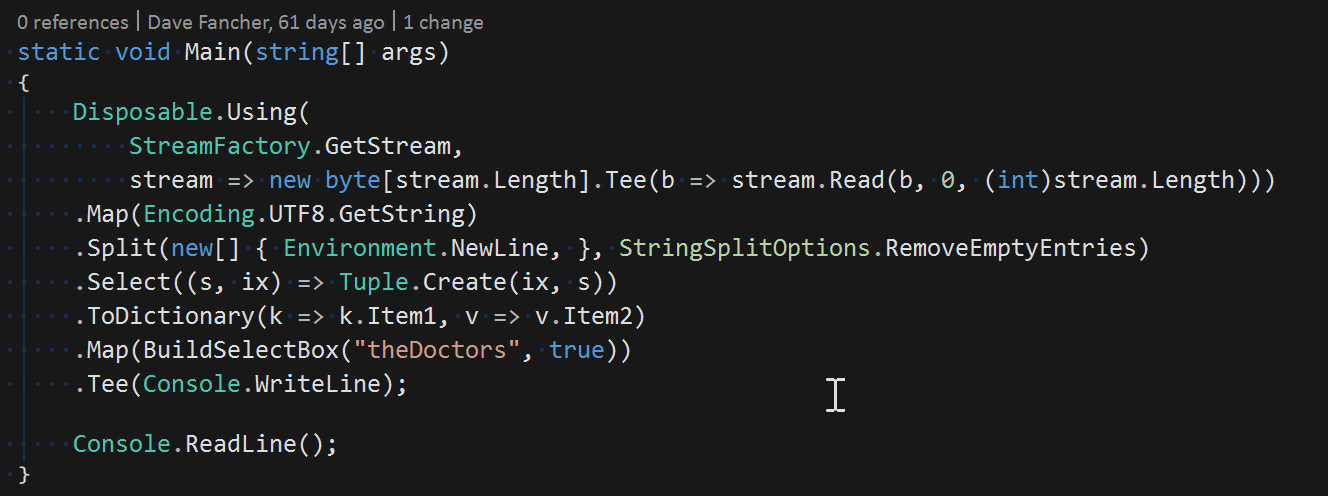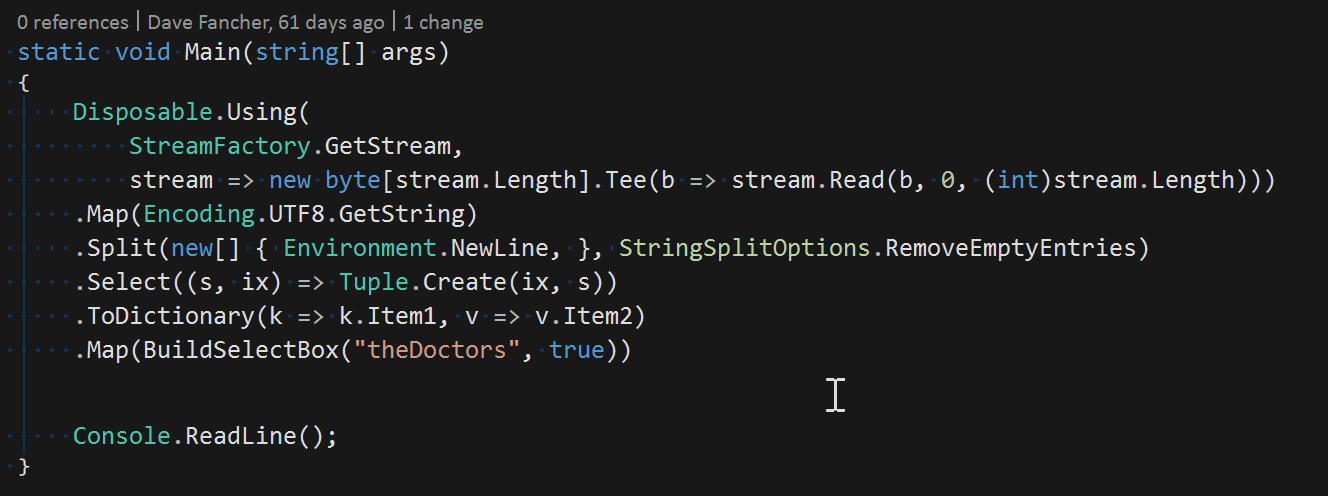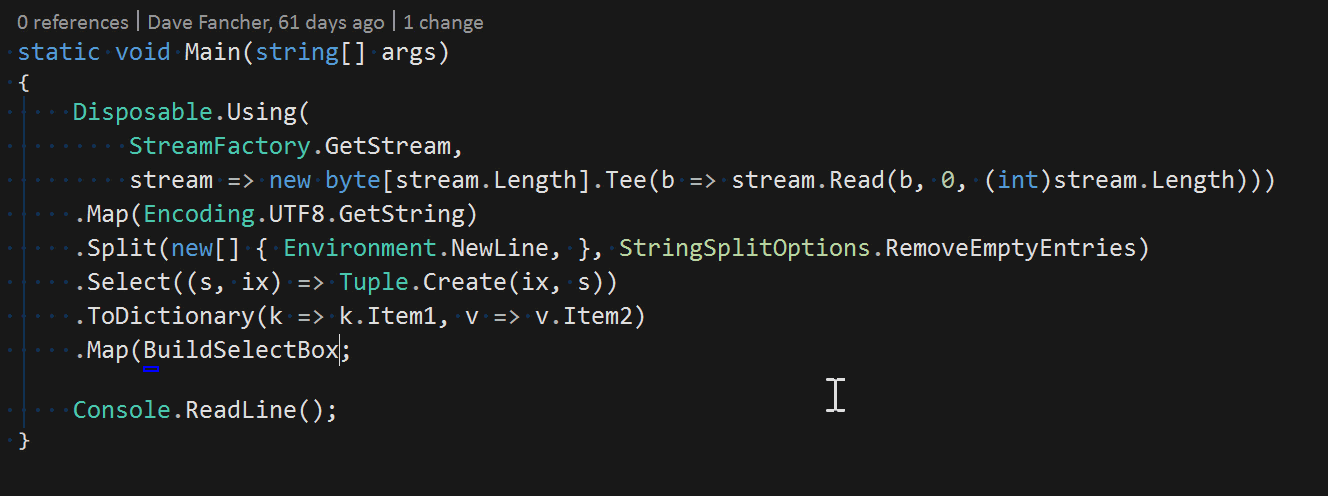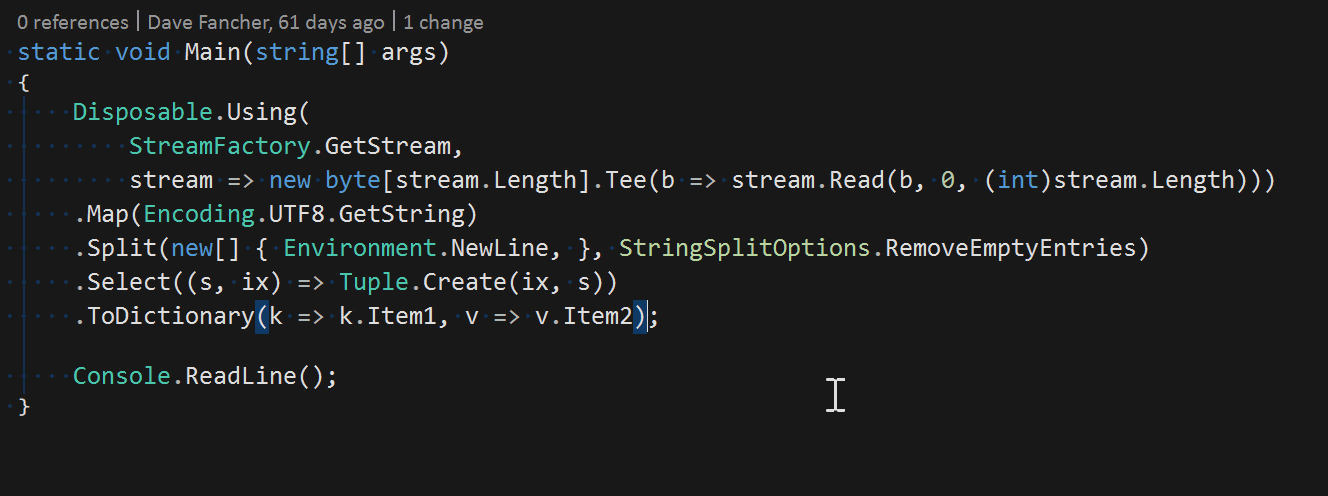
Consider a method to read a text file from a stream. By using the Disposable.Using method defined in the linked functional article, we can reduce the body to a single expression as follows:
public static string ReadFile(string fileName) =>
Disposable.Using(
() => System.IO.File.OpenText(fileName),
r => r.ReadToEnd());
Without taking advantage of C#’s functional features, such an expression wouldn’t be possible but in doing so we greatly extend the capabilities of this feature. Essentially, whenever the property or method body would be reduced to a return statement by using the described approach, you can use an expression-bodied member instead.
String Interpolation
Ahhh, string interpolation. When I first learned that this feature would be included in C# 6 I had flashbacks to the early days of my career when I was maintaining some Perl CGI scripts. String interpolation was one of those things that I always wondered why it wasn’t part of C# but String.Format, while moderately annoying, always worked well enough that it wasn’t particularly a problem. Thanks to a new string literal syntax, C# 6 will let us define format strings without explicitly calling String.Format by allowing us to include identifiers and expressions within holes in the literal. The compiler will detect the string and handle the formatting as appropriate by filling the holes with the appropriate value.
To define an interpolated string, simply prefix a string literal with a dollar sign ($). Anything that should be injected into the string is simply included inline in the literal and enclosed in curly braces just as with String.Format. We already saw an example of string interpolation but let’s take another look at the example:
public override string ToString() => $"Radius: {Radius}";
Here, we’re simply returning a string that describes the circle in terms of its radius using string interpolation. String.Format is conspicuously missing and rather than a numeric placeholder we directly reference the Radius property within the string literal. Just as with String.Format, we can also include format and alignment specifiers within the holes. Here’s the ToString method showing the radius to two decimal places:
public override string ToString() => $"Radius: {Radius:0.00}";
One of the things that makes string interpolation so exciting is that we’re not limited to simple identifiers; we can also use expressions. For instance, if our ToString method was supposed to show the circle’s area instead, we could include the expression directly as follows or even invoke a method:
public override string ToString() => $"Area: {PI * Pow(Radius, 2)}";
The ability to include expressions within interpolated strings is really powerful but, as Bill Wagner recently pointed out, the compiler can get tripped up on some things. Bill notes the conditional operator as one such scenario. When the conditional operator is included in a hole the colon character confuses the compiler because the colon is used to signify both the else part of the conditional operator and to delimit the format specifier in the hole. If this is something you run into, simply wrap the conditional in parenthesis to inform the compiler that everything within the parens is the expression.
Null-Conditional Operators
Finally we come to the fifth and final new feature in this list; a feature I consider to be a necessary evil: the null-conditional operators. The null conditional operators are a convenient way to reduce the number of null checks we have to perform when drilling down into an object’s properties or elements by short-circuiting when a null value is encountered. To see why this is useful consider the following scenario.
Imagine you have an array of objects that represent some type of batch job. These objects each have nullable DateTime properties representing when the job started and completed. If we wanted to determine when a particular job completed we’d not only need to make sure that the item at the selected index isn’t null but also that the completed property isn’t null, either. Such code might look like this:
DateTime? completed = null;
if(jobs[0] != null)
{
if(jobs[0].Completed != null)
{
completed = jobs[0].Completed;
}
}
WriteLine($"Completed: {completed ?? DateTime.MaxValue}");
That’s quite a bit of code for something rather trivial and it distracts from the task of getting the completed time for a job. That’s where the null-conditional operators come in. By using the null-conditional operators, we can reduce the above code to a single line:
WriteLine($"Completed: {jobs?[0]?.Completed ?? DateTime.MaxValue}");
This snippet demonstrates both of the null-conditional operators. First is the ? ahead of the indexer. This returns if the element at that index is null. Next is the ?. operator which returns if the member on the right is null. Finally, we see how the null-conditional operators can be used in conjunction with the null-coalescing operator to combine the giant if block into a single expression.
So why do I consider this feature a necessary evil? The reason is that I consider null to be evil, null references have been called The Billion Dollar Mistake, and Bob Martin discussed the evils of null in Clean Code. In general, nulls should be avoided and dealing with them is a costly nuisance. I think that these null-conditional operators, which are also sometimes collectively referred to as the null-propagation operators, will do just what that name implies – rather than promoting good coding practices where null is avoided, including the null-conditional operators will encourage developers to sloppily pass or return null rather than considering whether null is actually a legitimate value with the context (hint: it’s not). Unfortunately, null is an ingrained part of C# so we have to deal with it. As such, the null-conditional operators seem like a fairly elegant way to reduce null’s impact while still allowing it exist.
Wrap-up
There you have it, my five favorite C# 6 language features: auto-property initialization enhancements, using static, expression-bodied members, string interpolation, and the null-conditional operators. I recognize that some popular features such as the nameof operator and exception filters didn’t make the cut. While I definitely see their appeal I think they’re limited to a few isolated use cases rather than serving as more general purpose features and as such I don’t anticipate using them all that often. Did I miss anything? Let me know in the comments.